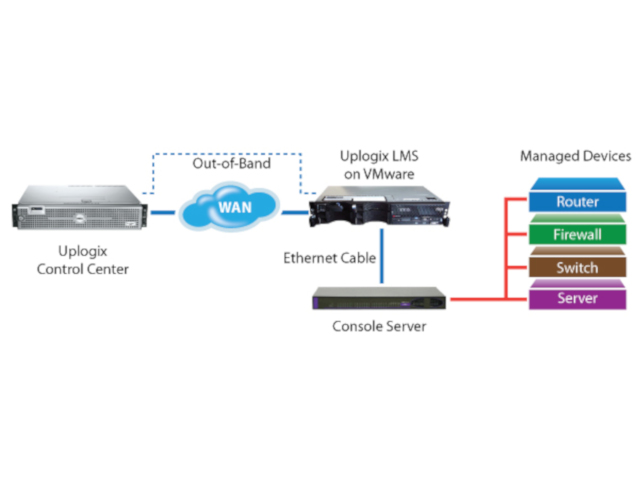

Not all console servers are created equal. With most, in-band management is the traditional model for network management with distributed gear and centralised management tools at the Network Operation Centre (NOC) but what do companies do when those centralised tools can’t reach the gear they are supposed to manage?
“What they should be considering is deploying out-of-band management, which seeks to remedy the challenges of in-band by adding a console server at the remote site connected to gears over the console port,” says Risna Steenkamp, ESM Business Unit Manager at value-added distributor Networks Unlimited Africa. “Using out-of-band, a remote admin can log into the console server and access the gear to attempt to fix the issue.”
Simply put, out-of-band management provides a secondary channel of communication to access and control the infrastructure assets of the production network.
But, says Steenkamp, going “beyond out-of-band” is where the true magic lives. She says it helps to see beyond out-of-band as a network administrator with a crash cart. Uplogix is securely connected to managed physical or virtual devices and the cloud, continuously monitoring, taking automated actions and providing remote access.
Although still reliant on human intervention and troubleshooting, out-of-band management can save support trips and speed resolution of issues, she says.
“Our partnership with Uplogix enables the deployment of decentralising network management software, which lives at a remote site in an intelligent console server. By utilising the connections to the network infrastructure, Uplogix continuously monitors the gear over the console port – not the network.
“Thanks to an out-of-band link, created to backfill NOC tools with current information, issues are discovered and verified in seconds, not minutes or hours, automated recovery actions are initiated and, for most issues, the network is returned to operation immediately.”
The benefits of automated remediation are clear. In a standard environment, network issues follow a typical timeline but standard tools, that poll over the network, only do so once every 15 minutes, on average. Once a problem is detected and before an admin is allocated to attend, it goes into a triage queue and trouble ticketing, starting with the most obvious solutions and proceeding through runbook steps.
Problems are generally solved remotely or with a service call.
With Uplogix, problems are detected and problem devices identified automatically within 30 seconds, way sooner than traditional network polls, and, with automated runbook actions, resolution times are compressed significantly.
Achieving cyber resiliency with Uplogix
Today, we have access to thousands of cybersecurity products fighting an ongoing war with cybercriminals, but investing in cyber resiliency is a pragmatic approach to reducing your overall cyber risk, says Steenkamp.
The NIST’s Cybersecurity Framework has been designed to improve cybersecurity across sixteen critical infrastructure industries and build up from a basic core of functions based around the structure of Identify, Protect, Detect, Respond and Recover – Uplogix provides capabilities that address all of these pillars and more.
Protect – With Uplogix, device management is conducted from a separate control panel with dedicated connections and encrypted traffic.
Detect – Since Uplogix is not dependent on the network to manage network infrastructure, additional data can be collected and all traffic over the console port can be saved in a buffer area and archived.
Respond – Uplogix incorporates a rules engine that automates pre-scripted actions in response to specific situations and data. The system can also push configuration changes to one device or thousands to lock down network services and limit the impact of a breach (or determine its impact).
Recover – All configurations are stored locally and can be applied to remove malicious actions after an event or as part of a scheduled clean sweep. Safe mode configurations can be applied as needed, then removed to return the network to normal.
“Organisations are realising that they not only need to be focussed on preventing hacks but also on preparing for what to do after an event occurs,” says Steenkamp.
1. In the moments after an event is identified, Uplogix pushes pre-staged configuration changes to the network, placing it in Safe Mode with only essential services available.
2. Then, if the network is down, its out-of-band connections act as a backup link to remote sites (in effect, serving as a failover site) and its rapid response capabilities allow it to rebuild affected devices rapidly with golden or updated configurations.
3. And lastly, the system provides detailed audit and compliance reporting, so you will always know who did what, and with what, to affect your critical network and communications devices.
“Uplogix tells us the average detection time for network intrusions can range from days to months with the average cost of a data breach topping $3 million, and that doesn’t even factor in ongoing business impacts like negative brand reputation,” says Steenkamp.
“Managing the network grows increasingly more challenging with the infrastructure becoming more widely distributed and complex as time goes by. Today might be a good time to consider a new approach for managing remote locations, one that overcomes the restrictions of traditional tools and removes the admin associated with managing remote locations while reducing costs and risks to the network.”

